Methodology
At Predictive Heuristics we use a bevy of state of the art techniques and methodologies to bring you the best in risk analysis and prediction.
EBMA
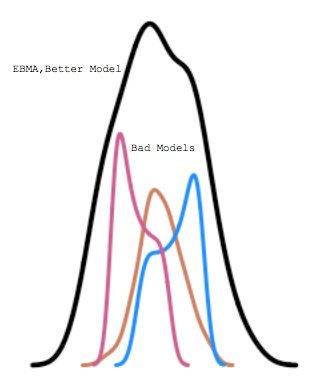
In 1907 Sir Francis Galton analyzed data from a weight-judging competition at the West of England Fat Stock and Poultry Exhibition. To compete for prizes, about 800 individuals paid to guess the weight of the ox once it had been slaughtered and dressed. The remarkable finding, repeated in many ways since, is that the average of all the guesses was within one percent of the correct wight, yet no individual guess was that close. This principle is known as the wisdom of crowds. This suggests it is too hard to build a single model that is perfect, but rather one is better off to build lots of imperfect models and average across them. EBMA improves prediction by pooling information from multiple forecast models to generate ensemble predictions.This approach has been extended to political forecasting models (here and here) and incorporated successfully into ongoing forecasting efforts undertaken by government and commercial enterprises.
Missing Data
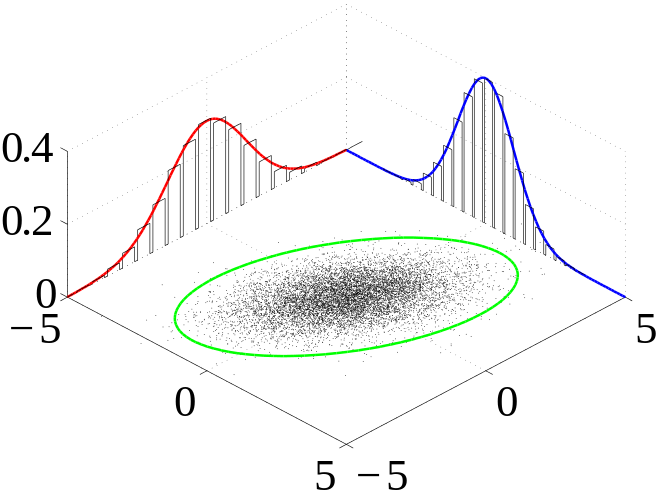
Despite the overwhelming avalanche of data that characterizes our world, often times there is a lot of information that simply isn't available. This missing data problem was swept under the rug previously, leading to biased models and erroneous predictions. Now there are several well known techniques to impute missing data. Few of these are ideal for predictive models, and most of them are computationally cumbersome. We have adapted an approach that is both fast and easy, reducing the computational barriers while maintaining a principled flexibility. Ironically, this modern approach is based on a fundamental theorem from 1959 (Sklar's theorem). We use a type of copula method applied to rank order transformations to reduce bias in our models and predictions (Fast and Easy Imputation of Missing Social Science Data). Copulas are newly constructed distributions that link together interdependent random variables, which can be continuous, ordinal, or categorical.
Split Population Modeling
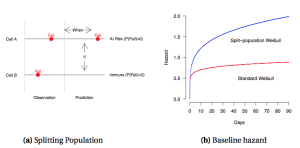
Many models assume that the differences can be captured by looking at the right variables. Risk is probably different, and some places are immune from risk, while others are rife with risk. The risk of debilitating social protests in New Zealand is close to zero, while it is probably much higher in the Ukraine. Some models are able to split the cases being analyzed into two groups: those with substantial risk and the others which are essentially immune to the kind of events being studied. This approach is known as split population modeling, one of the ways that Predictive Heuristics tackles the analysis of risk in the entire world.
Multilevel Modeling
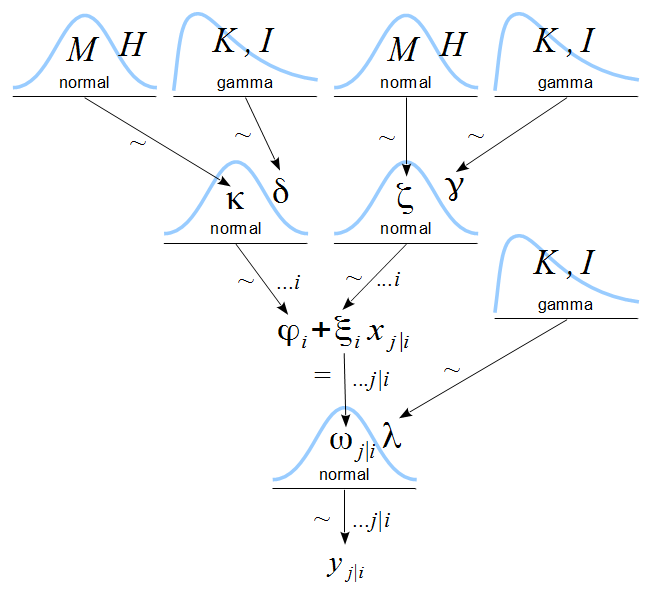
Many standard approaches to analyzing risk in countries only use variables that are measured at the country level. But in actuality, there are global variables-say oil prices-that impact all countries in some important fashion. In the same way, countries are interrelated such that bank failures in Greece affect the economies in many countries around the world, including its immediate neighbors in Europe. And, too sine groups of countries-say the OECD countries-have institutions that affect and constrain their behaviors as well. In reality variables from many different levels, global, regional, country-level, and even within country-affect the risk environment. As such, we employ a type of approach that embraces all of these kinds of aspects of the empirical world to aid in understanding risk in specific countries.